Predicting the MLB Draft: Creating a Model
The MLB Draft starts on June 10th, with this year being five rounds this year with all undrafted free agents capped at $20,000. There are three types of people when it comes to risk: risk averse, risk neutral, and risk taking. Given the circumstances this year, the risk averse general manager will take a college player as they are more likely to sign, have a higher floor and are more likely to make the MLB. These GM’s are trying to keep their job and having a draft pick make the majors in 2022/2023 will be proof of the draft process. The risk neutral GM will take best player available, which is likely the ideal strategy. The risk taker will take more loud tools, similar to what Mike Hill and the Marlins have targeted over the years in trades and drafts. In this year’s draft, the risk will be the tooled up high schoolers, who should be more available later in the draft. The prep players will have more power in negotiations, teams will want to their few draft picks. College players have less leverage and would have to weigh the opportunity cost of going back for a senior year. A high schooler can go to junior college and be eligible again in 2021. For the 2020 draft, I do expect more college players to be selected.
Despite this, we can model the draft and predict where a given prospect will go in the draft. This model is more simplified, using only Fangraphs prospect draft data, but adding in other prospect sources such as Baseball America, MLB Pipeline, Kiley McDaniel at ESPN, and Keith Law at The Athletic and previously ESPN. Mock draft data could also be included in the model, something that ESPN did for the NFL Draft, which is what ultimately inspired this post.
The data input on the model is Fangraphs’ 2014-2019, cleaned to only prospects that are ranked (i.e. a player such as Jayson Schroeder, who went 66th overall to the Astros in 2018, is not included as they were ranked as HS-P-4). The data is also cleaned so that Luke Heimlich was removed, given he was undraftable, adjusted so that two-way players are only listed at the position they play in pro-ball (this does penalize Brendan McKay, who as a true two-way player is only listed as a LHP, and for the 2020 prospects, the first listed position. Again, this is just a simple model for projecting a draft, and the elite players like McKay who are true two-way players are rare.
Included in the model is the prospect’s FanGraphs ranking, age, position, school type (college vs high school), and future value. As a side tangent, there are three schools of thought when grading prospects: Theo Epstein Model (using letter grades), Future Value (WAR based), and Overall Future Potential (75th percentile outcome), these are broken down in the book Future Value by Eric Longenhagen and Kiley McDaniel. A quick comparison of Theo’s model (used by the Red Sox, Cubs, Diamondbacks, etc.) and the Future Value model are below:
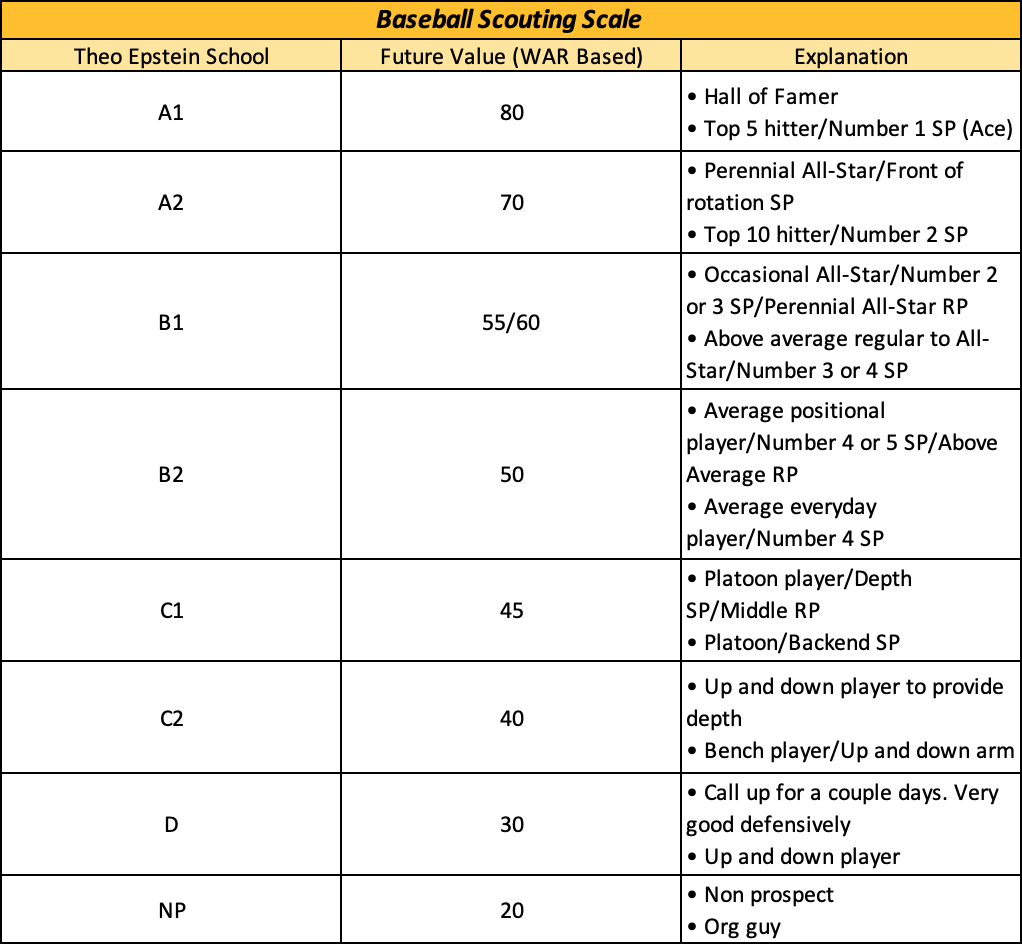
Now that we have the inputs, we need to know where the ranked prospects were drafted between 2015-2019, which comes from using Chris Long’s web scraper. Since the goal is to predict where each player is drafted, we’ll use a Bayesian logit model (bayespolr in from the “arm” package in R). The model is then pick = rank + position + age + school + FV. Looking at the Tigers selection of 1.1, we get the following probabilities for the selection:
| Rank | Player | Position | Age | School | FV | 1.1 Prob |
|---|---|---|---|---|---|---|
| 1 | Spencer Torkelson | 1B | 20.8 | College | 55 | 29.63% |
| 2 | Austin Martin | CF | 21.2 | College | 55 | 26.17% |
| 6 | Nick Gonzales | 2B | 21.0 | College | 50 | 4.25% |
| 3 | Asa Lacy | LHP | 21.0 | College | 50 | 3.39% |
| 4 | Emerson Hancock | RHP | 21.0 | College | 50 | 3.11% |
Spencer Torkelson is the projected first overall pick, consistent with most of the mock drafts, but Austin Martin, the centerfielder from Vanderbilt, is right behind him. Jim Callis of MLB Pipeline interviewed executives on their view of who should go first overall, and Asa Lacy’s name apparently did come up. Nick Gonzales rises to the third highest probability given he is a college middle infielder, allowing him to jump up to the third highest probability at 4.27 percent, where high school outfielder Zac Veen is sixth at 2.86 percent.
If we were to place a bet on the market, our model would indicate that Torkelson is a +237 bet, (100/0.2963)-100, but we need a lower probability than just the theoretical 30 percent to control for the margin of error. If we determine that number to be anything at 3.0 points, then a +270 bet would be worth it. For example, if the market is at that +270 and I bet $5 on Torkelson being 1.1 and he is selected at that spot, I would win $13.50 in the market. Using our model: winning = $13.50(0.2963) – $5(1-0.2963), which comes out to be a win of $0.48. Using the other sources of data would better this model and could be used in the market.
Where this could most be used is for teams deciding on when to take a player. Let’s take the Baltimore Orioles for example, who pick at 30th overall in the Competitive Balance Round A and then 39th in the second round. Say they like three players at picks 30 and 39 and they will take two of them if available at those picks. Assume Baltimore has C.J. Van Eyk (pitcher from Florida State), Jordan Westburg (shortstop from Mississippi State), and Carson Montgomery (a high school right-handed pitcher) as the top three prospects remaining in some order. Generating the probability that the player is around at any given pick (1-sum(n-1), where n is pick number), we see the following:
| Player | Position | Available at 30 | Available at 39 |
|---|---|---|---|
| Van Eyk | RHP | 56.49% | 39.25% |
| Westburg | SS | 53.89% | 36.77% |
| Montgomery | RHP | 77.11% | 62.63% |
All three players are 45’s and at pick 30 they have to decide who to take with all three being available. Van Eyk or Westburg should be the selection at pick 30 knowing that we will be more likely to get Montgomery at pick 39 than the other two players. Even if Baltimore has Montgomery ranked as the best available, it’s more likely than not that he is available at pick 39 compared to the other two players. This type of model can help inform what picks might be reaches, when to decide to be patient and let the board fall your way, or when to be aggressive and take a player that is really liked that might seem to be a reach, but the likelihood they are not there with your next pick is lower than another player you like. This would be similar to the Pirates taking Cole Tucker in 2014, a player that they liked, thought would’ve been a top 10 pick if he was an 18-year-old senior in 2015, and knew wasn’t going to be available at pick 39.
This model also falls short, not just in terms of using only one data source as described above, but also the signability concerns of high school players. In the NFL draft, that is not an issue (though ESPN did model for draft pick trades and team needs) but is a concern here. High school players can slide down the board and as a result the draft because of this. This simplified model is created to show approximate probabilities (ones approved with more data from other sources) that can help in the gambling market but also to understand why a team will take a certain player earlier than what is anticipated.
*This post has been updated to fix an error where “RHS” and “LHS” were not cleaned to “RHP” and “LHP”*
0 Comments on “Predicting the MLB Draft: Creating a Model”